1. 서론
텍스트 분류 text classification - 하나 혹은 그 이상의 클래스 라벨을 각 문헌에 연결짓는 행위 즉, 문헌을 클래스에 넣는 과정
클래스 - 라벨에 의해 표현될 수 있는 내용을 가진 문헌을 넣을 집합. 분류된 그룹. (=범주 category )
ex) 심장 수술 클래스 = { 심장 질환을 다루는 수술 절차에 관한 문헌 }
=> 주제분류( topic classification) 클래스 라벨이 문헌의 주제를 나타냄.
-- 클래스 관련 문제 : 문헌 집단을 라벨링 없이 부분집합으로 나누는 것. 각각의 부분집합은 라벨이 붙어 있지 않기 때문에 클러스터(cluster)라고 한다. (= text clustering)
텍스트 분류 = 정보를 정리해서 데이터의 이해와 해석을 돕는다.
2. 텍스트 분류의 특징
기계학습 : 데이터로부터 패턴을 학습하는 알고리즙의 개발과 설계에 관한 인공지능의 분야 중 하나.
정보검색에서 텍스트 분류는 기계학습에 영향을 받은 핵심 분야.
기계 학습은 문제를 해결하기 위한 맞춤 코드(custom code)를 작성하지 않고도 일련의 데이터에 대해 무언가 흥미로운 것을 알려줄 수 있는 일반 알고리즘(generic algorithms)이 있다는 아이디어입니다. 코드를 작성하는 대신 데이터를 일반 알고리즘에 공급하면, 데이터를 기반으로 한 자체 로직이 만들어 지게 됩니다.
예를 들어, 이러한 알고리즘의 한 종류가 분류(classification) 알고리즘입니다. 이 알고리즘을 사용하면 데이터를 서로 다른 그룹으로 분류할 수 있습니다. 손으로 쓴 숫자를 인식하는 데 사용 된 것과 동일한 분류 알고리즘을 그대로 코드 변경없이 사용해서, 이메일을 스팸과 스팸이 아닌 것으로 분류 할 수도 있습니다. 결국 동일한 알고리즘이지만 다른 학습 데이터를 제공하면 다른 분류 로직이 자동으로 만들어지게 됩니다.
기계학습 알고리즘
- 학습 단계 : 입력데이터에 있는 패턴정보를 표현하는 모델이나 함수를 만들기 위해 사용된다.
머신러닝에서 학습(Learning) 이란 목표값과 실제값의 오차에 근거해서 최정의 가중치가 되도록 업데이트(학습) 시키는 것.
기계학습 알고리즘의 3가지 타입
- 지도학습 ( supervised learning)
- 자율학습 ( unsupervised learning)
- 준 지도 학습( semi-supervised learning)
지도학습 ( supervised learning)
훈련데이터(training data) 를 입력받아 함수 추출하는 것. 즉 정답이 있는 데이터로 학습하는 것.
Supervised Learning process

A resulting predictive model

출처 - http://www.java-machine-learning.com/blog/supervised-learning/
텍스트 분류의 경우 훈련데이터는 문헌과 클래스의 쌍으로 구성. 문헌-클래스 쌍은 전문가가 분류한 것, 제공된 문헌의 적절한 클래스를 나타낸다. 이 훈련 데이터는 분류 함수 추출하기 위해 사ㅛㅇ되고 함수는 새로운 데이터에 맞는 클래스의 예측에 쓰일 수 있다.
자율학습(Unsupervised learning)
주어진 훈련데이터가 없는 것. 자율 학습알고리즘은 입력 데이터의 타고난 특성을 가지고 패턴을 감지하는 것이다. 신경망 모델, 독립 성분 분석, 클러스터링을 포함하며 텍스트 분류에서 클러스터링이 중요함.
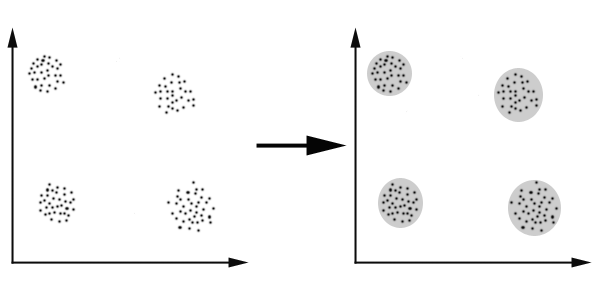
클러스터링 작업에서는 유사한 데이터 인스턴스가 그룹화되어 데이터 클러스터를 식별한다. 이 알고리즘은 레이블이 없는 학습 데이터 셋을 처리하고 인스턴스 특성을 기반으로 그림을 세 개의 다른 데이터 클러스터로 그룹화한다. 클러스터에 비슷한 데이터를 그룹화할 수 있는 능력에도 불구하고 예제의 알고리즘은 그룹에 대한 레이블을 식별할 수 없다. 그룹의 의미를 식별할 수 없는 것.

준 지도 학습( semi-supervised learning)
예측 향상시키기 위해서 적은 양의 라벨링된 데이터와 좀 더 많은 양의 라벨링되지 않은 데이터를 이용하는 것이다.
텍스트 분류 문제
문헌 컬렉션 D 와 각각의 라벨 L 가진 클래스 나타낸 집합 C = { c1, c2, ..... , cL }
텍스트 분류 함수는 이진함수 F : D X C -> { 0 ,1 }
1의 값이 부여되면 문헌이 그 클래스에 속하는 것. 0의 값이 부여되면 속하지 않는 것.
-> 지도 및 자율 텍스트 분류 알고리즘에 적용됨.
분류함수에 아무런 제약이 없다면 두개 이상의 클래스가 하나의 문헌에 배정되기도 하는데 이러한 경우의 분류함수를 다중-라벨(multi-label) 타입이라고 한다.
만약 분류함수가 각각의 문헌에 하나의 클래슬르 지정하도록 제한하는 경우 단일-라벨(single-label)타입이라고 한다.
단일-라벨 타입일 때 문헌-클래스 쌍을 결정하는 문제를 넘어서서 어떤 클래스가 주어진 문헌에 가장 적합한 것인지 판단해야하기 때문에 더 어려워진다.
분류함수는 특정 문헌이 특정 클래스에 속하는지의 이진결정 이외에 문헌의 클래스 소속도(degree of membership)를 계산하도록 만들어질 수도 있음. 이런 경우 많은 문헌들이 한 클래스의 후보가 되며 랭킹 함수는 문헌 dj의 텍스트와 클래스 cp의 라벨 입력받았을 때 각 쌍의 랭킹값을 부여한다. 나아가 문헌이 클래스에 속하는지 아닌지에 관한 결정을 하기 위해서 랭킹값을 사용할 수도 있는데 예를 들어 F(dj, cp)의 랭킹이 제시된 클래스의 임계값(threshold value)과 같거나 크다면 문헌 dj가 클래스 cp에 속한다고 말할 수 있으며 반대상황이라면 속하지 않는다는 말이 된다.
텍스트 분류 알고리즘
- 자율 알고리즘
이용 가능한 훈련데이터가 없는 큰 컬렉션에 적합
- 지도 알고리즘
지도(supervised) 알고리즘
: 사람에 의해 얻어지거나 사람이 생산한 정보를 이용하는 경우이다. 일반적인 경우 클래스 집합과 각 클래스를 위한 문헌의 예가 제공되는데 이 예는 전문가에 의해 결정되고 훈련 집합을 구성한다. 이 훈련 데이터는 분류 함수가 학습하는데 사용되며 일단 함수가 학습되고 나면 새로운 문헌을 분류하는데 이용한다.
3. 자율 알고리즘
클러스터링(clustering)
제공된 입력데이터는 오직 컬렉션의 문헌이고 어떤 클래스 라벨도 주어지지 않은 상황을 가정했을 때 이 상황에서 분류함수의 작업은 문허을 그룹이나 클러스터로 나누는 것이며 이를 클러스터링이라고 지칭한다.
텍스트 클러스터링 : 문헌 컬렉션 D 가 주어졌을 때 텍스트 분류 방법은 미리 정의된 기준에 의해서 K개의 클러스터로 문헌들을 자동으로 분류한다.
. 즉 sample 들에 대한 지식없이 similarity (유사도) 에 근거하여 cluster 들을 구분한다. 패턴 공간에 주어진 유한 개의 패턴들이 서로 가깝게 모여서 무리를 이루고 있는 패턴 집합을 cluster (군집) 이라하고 무리지워 나가는 처리 과정을 clustering 이라 한다.
클러스터링은 하나의 데이터를 여러개의 부분집합 (clusters) 으로 분할하는 것을 의미하며, 그때 각 부분집합에 있는 데이터는 몇가지의 공통된 특징 (trait)을 공유하는데, 그것은 몇가지 거리 측정법을 사용하여 유사도 (similarity or proximity)를 계산함으로써 이루어진다. 데이터 클러스터링은 크게 두가지, 즉 hierarchical clustering 과 partitional clustering 으로 나눌 수 있다.
hierarchical clustering 은 agglomerative (bottom-up) 또는 divisive (top-down) 일 수 있다. 각 요소들로부터 시작한 클러스터들이 계층구조를 이루는 것이며, tree 구조를 이루며 한쪽 끝에는 각각의 요소가 있고 다른쪽 끝에는 모든 요소를 가지를 단 하나의 클러스터가 있다.

partitional clustering 은 cluster 의 계층을 고려하지 않고 평면적으로 clustering 하는 방법으로 일반적으로 미리 몇 개의 cluster 로 나누어 질 것이라고 예상하고 cluster 의 개수를 정하는 것이다 ............ (Wikipedia : Data Clustering)
출처 : http://www.aistudy.com/pattern/clustering.htm
클러스터링 예시
하와이에 있는 호텔 웹페이지를 5개의 클러스터로 그룹화할 때 각 클러스터는 같은 섬에 있는 호텔로 구성된다(기준= 지리적 근접도).
이러한 클러스터링은 사람에게는 자연스럽게 이해되지만 자동 절차에 의해서는 호텔 위치에 대한 용어를 뽑아내는 것은 인간의 이해력 없이는 알 수 없다.
라벨을 붙여야 한다면 더 어려워진다. 라벨을 붙이는 작업은 호텔이 있는 섬의 이름을 각 클러스터에 붙이면 된다. 하지만 자동으로 생성된 라벨은 다르게 나타나는경향이 있으며 특별한 의미를 전해주지 못한다. 자동 라벨링은 어려운 문제를 내포하고 있음.
그러나 이해하는데 문제가 있어도 클러스터링은 데이터간 본연의 특성 간파하는 통찰력 가져다 준다.일반적인 문헌 클러스터링에 대해 설명하기 위하여 널리 알려진 분할 알고리즘인 K-평균(K-means)과 K-평균의 변형인 이분법 K-평균(Bisecting K-means)에 대해 논의한다. 또한 응집 클러스터링(Agglomerative Clustering)의 세 가지 변현인 단일-링크(single-link), 완전-링크(complete-link), 평균-링크(average-link) 알고리즘이 있다.
K-평균 클러스터링(K-means Clustering)
생성될 클러스터 갯수 K가 입력되면 각 클러스터는 중심값(centroid)으로 표현되고 각 문헌은 가장 중심에 가까운 값을 가진 클러스터로 할당되면서 K개의 클러스터들로 나뉘어진다. 이 작업이 일단 끝나면 각 클러스터의 중심값은 다시 계산되고, 모든 처리는 중심값이 바뀌지 않을 때까지 계속 반복된다. 일괄처리 모드(batch mode)로 작동된다. 일괄처리 모드는 모든 문헌들이 분류된 후에 중심값이 재계산된다. 할당 단계와 갱신 단계가 중요한데 할당 단계에서 각 문헌은 중심값과 가장 가까운 클러스터에 할당되고, 갱신 단계에서 새롭게 할당된 문헌들을 고려하여 중심값이 조정된다.
같은 cluster에 속하는 데이터들의 inner similarity를 증가시키는 방향으로 cluster 형성한다.
가정 ) 데이터가 평균을 구할 수 있도록 실수의 좌표를 가져야 한다.
예시)
1.

cluster의 개수를 3개로 정한다.
K 개의 초기 centroid(클러스터의 중심이 될)를 랜덤하게 선택한다.

각각의 object를 자기자신에게서 가장 가까운 centroid ki에 할당한다.
같은 centroid에 할당된 object들의 평균을 구한다.
3.

구한 평균값을 2번 째 centroid 값으로(클러스터의 중심으로) 설정한다.
4.

각각의 object를 자기자신에게서 가장 가까운 centroid ki에 할당한다. (2번째 centroid)
같은 centroid에 할당된 object들의 평균을 구한다.
5.

구한 평균값을 3번째 centroid 값으로 (클러스터의 중심으로) 설정한다.
각각의 object을 자기자신에서 가장 가까운 centroid ki에 할당된다.( 3번째 centroid)
각각의 centroid에 할당된 object들의 멤버쉽이 변화가 없을 때까지 반복한다. (= 더 이상 데이터 자신이 속한 클러스터가 변하지 않는 것을 의미한다.)
출처 https://www.slideshare.net/JeonghunYoon/05-k-means-clustering-kmeans
아래와 같이 문헌 dj를 가중치 용어 벡터로 표현하자.

w i,j는 문헌 dj의 용어 ki의 가중치이고 t는 어휘 크기이다.
K-평균 클러스터링-일괄처리 모드
1. 초기 단계

무작위로 K개의 문헌들을 컬렉션에서 선택한 다음에 각 문헌을 별개의 클러스터에 배정한다. 이 문헌들은 초기 클러스터의 중심값이 된다. dj를 초기에 선택된 문헌 중 하나라고 하고 cp는 배정된 클러스터라고 했을 때 그에 상응하는 중심값이 됨.
2. 할당 단계

컬렉션에 있는 N개의 각 문헌을 가장 가까운 중심값을 가진 클러스터에 할당한다. 즉 문헌에서 최소거리에 있는 클러스터를 뜻한다. 최소 거리는 최대 유사성을 뜻하게 된다. 유사성 계산을 위해 백터 모델의 코사인 공식을 이용한다.
* 벡터 모델 : 가중치를 할당해 유사도를 계산함. 설명 http://euriion.com/?p=548
3. 갱신단계

벡터가 배정한 문헌을 기반으로 각각의 클러스터의 중심값을 다시 계산하거나 조정한다. size(cp)가 클러스터 cp의 문헌 숫자라고 하면 상응하는 클러스터 중심값을 재계산한다.
4. 최종단계 : 중심값이 변하지 않을 때까지 2,3번 단계를 반복한다.
k-평균 클러스터링-온라인 모드
온라인 모드는 각 문헌이 분류된 후에 중심값이 재계산된다. 온라인 k-means를 사용하면 새 데이터를 수신 할 때 모델을 업데이트 할 수 있습니다.
1. 초기단계 : 무작위로 문헌 K개를 선택하고 초기 중심값으로 이용한다.
2. 할당단계 : 각각의 문헌 dj는
- 문헌 dj를 중심값에 가장 가까운 클러스터에 할당한다.
- 클러스터의 중심값을 재계산한다.
를 반복 시행한다.
3. 최종단계 : 2번 단계를 중심값이 변하지 않을 때까지 반복한다.
K-평균 클러스터링은 어떤 상황에서는 잘 작동되지만, 다른 상황에서는 잘 작동되지 않을 수도 있다. 클러스터의 갯수 K의 선택이 이 알고리즘에서 중요한 단계가 되고 또한 초기 중심값의 선택에 영향을 받음에 따라 실행 횟수가 결과에 영향을 미친다.
이분법 k-평균 (Bisecting K-means)
클러스터 계층을 만드는데 클러스터는 각각의 단계에서 두 개의 클러스터로 나뉘어진다. k=2로 시작해서 k-평균을 반복해서 적용한다.
1. 초기 단계 : 모든 문헌들을 단일 클러스터에 할당한다.
2. 분할 단계 : k=2 를 가지고 가장 큰 분류에 k-평균을 적용한다.
3. 선택 단계 : 만약 '어떤 클러스터도 주어진 임계값보다 더 작지 않다' 와 같은 중지 기준이 만족하면 실행이 중지된다. 중지 기준이 만족한다면 실행이 중지된다. 중지 기준에 만족하지 않는다면 가장 많은 문헌들을 가진 클러스터를 선택하고 다시 2단계로 돌아간다.
계층적 응집 클러스터링(Hierarchical Agglomerative Clustering)
클러스터 계층을 새로이 만들고 이 방법은 큰 클러스터를 더 작은 클러스터로 분할하거나 이미 정의된 클러스터를 더 큰 것으로 응집시킨다.
각 데이터에서 시작해서 유사한(즉, 가 가까운) 데이터끼리 순차적으로 군집을 묶어나가는 응집형 계층적 군집
거리 행렬을 가지고 군집 간 유사성을 측정해서 모든 데이터가 하나의 군집으로 응집/병합될 때까지 반복적으로 군집화를 수행합니다.

분석 목적에 맞는 거리 측도를 선택해서 가능한 모든 쌍의 데이터 간 거리를 계산하면 됩니다. (유사성 측도로 거리를 사용하면 => "거리가 짧을 수록 유사하다"고 해석)

출처: http://rfriend.tistory.com/tag/응집형 계층적 군집화 알고리즘 [R, Python 분석과 프로그래밍 (by R Friend)]
1단계 : N개의 문헌 집합과 N.N 유사성(거리) 행렬을 입력받는다. 행렬의 값들은 예를 들면 벡터모델의 코사인 공식으로 계산되어 주어질 수 있다.
2단계 : 각 문헌을 각각의 클러스터에 할당하여 그 결과 클러스터 당 문헌 하나를 가진 N개의 클러스터들이 만들어진다.
3단계 : 가장 유사한 클러스터 쌍을 찾아서 하나의 클러스터로 합치면 클러스터 수는 1씩 줄어든다. 새로운 클러스터는 하부 클러스터를 포함하는 한 단계 위의 노드로 표현된다.
4단계 : 새로운 클러스터와 기존의 클러스터 사이의 유사성을 클러스터가 포함하는 문헌들의 함수를 이용해서 재계산한다.
5단계 : 모든 문헌들이 클러스터링되어서 단일클러스터의 크기가 N이 될 때까지 3단계와 4단계를 반복한다. 여러 중간 클러스터들과 초기 단일 문헌 클러스터들은 결국 하나의 트리를 이룬다.
4단계에서 두 개의 클러스터 사이의 유사성(거리)을 계산하는데 클러스터 유사성(cluster similarities) 클러스터 거리가 계산되는 방식에 따라 단일-링크(single-link), 완전-링크(complete-link), 평균-링크(average-link) 세 개의 알고리즘으로 나눌 수 있다.

단일-링크 알고리즘
클러스터 거리는 한 클러스터의 문헌 하나와 다른 클러스터의 문헌 하나 사이의 거리중에서 가장 짧은(shortest) 거리(가장 큰 유사성)로 한다.
"최단(MIN) 연결법"이라고도 하며, 다른 군집에 속한 가장 가까운 두 점 사이의 거리를 군집 간의 거리로 측정하는 방법입니다.
http://rfriend.tistory.com/202?category=706119

완전-링크 알고리즘
클러스터 거리는 한 클러스터의 문헌 하나와 다른 클러스터의 문헌 하나 사이의 거리중에서 가장 긴(largest) 거리(가장 작은 유사성)로 한다.
단일(최단) 연결법이 군집 간 거리를 잴 때 다른 군집의 점들 중에서 가장 가까운 두 점 간의 거리를 사용하였다면, 완전(최장) 연결법은 반대로 '다른 군집의 점들 중에서 가장 멀리 떨어진 두 점 간의 거리를 가지고 군집 간 거리를 잽니다.
http://rfriend.tistory.com/203?category=706119

평균-링크 알고리즘
클러스터 거리는 한 클러스터의 모든 문헌과 다른 클러스터의 모든 문헌 사이의 거리의 평균거리로 한다.
http://rfriend.tistory.com/204?category=706119
'정보검색론' 카테고리의 다른 글
| 카이제곱검정, F-척도 (0) | 2018.01.18 |
|---|---|
| 웹 수집기(Web Crawler) (0) | 2018.01.18 |
| 텍스트 분류 (0) | 2018.01.17 |
| [파일구조] B tree 와 B+ tree (0) | 2018.01.16 |
| hash 자료형 (0) | 2018.01.16 |


